Nobody should hand-code a data table in 2026
Mar 16, 2026 | by Maximilian Kaske | [engineering]
The data-table-filters project has been live for 1.5+ years. Filters, sorting, infinite scroll — the whole thing. It worked. People starred it. Bigger companies like Supabase took inspiration for their logs dashboard.
But adopting it in another project wasn't straightforward. You'd have to clone the repo, wire together multiple files just to add a column — columns in one file, filter config in another, sheet fields in a third, Zod schema somewhere else. Change one, forget the others, wonder why nothing works.
It was a good idea. It was a bad DX.
Then the shadcn components registry and agent skills landed — and suddenly the pieces fit. We can ship code people own and an AI that knows how to set it up. No CLI installer needed. No npm package needed. And for AI coding tools, importing files via CLI keeps the context window lean — no need to overbloat it by copy-pasting entire repos worth of code.
We rebuilt the entire developer experience — refactoring code, improving composability, and shipping modern distribution — without compromising the UI taste. Here's what we shipped.

State management adapters
Before, the table was married to nuqs (URL search params). If you didn't want URL state, tough luck.
We built a BYOS (Bring Your Own Store) architecture with three adapters that all implement the same interface:
- Memory — state lives in React refs. No URL, no external store. The default when getting started.
- nuqs — state syncs to URL search params. Shareable links, back button works, SSR-friendly. The original behavior, now pluggable.
- zustand — state lives in a zustand store via a
createFilterSlice()helper. Drops into existing zustand setups.
All three support pause/resume (for live-streaming mode) and work with React 18's useSyncExternalStore. Swapping adapters is one line — the table doesn't know or care which one you're using.
Adding a new store to the mix is straightforward too. Just implement the StoreAdapter<T> interface and you're good to go.
Single source of truth: the table schema
This was the big refactor. Before, defining a table meant keeping five separate files in sync:
columns.tsx— TanStack column definitions, cell renderers, sizingconstants.tsx— filter field configs, sheet field configs, UI propertiesschema.ts— Zod validation for data rows AND a separate BYOS filter schema with serialization delimiterssearch-params.ts— nuqs parser derived from the filter schemastore.ts— zustand slice derived from the filter schema
Adding a column? Edit all five. Renaming a field? All five. Changing a filter type from checkbox to slider? Update the schema, the constants, and the columns file — and hope you didn't miss the filterFn.
The solution: define a column once, derive everything else.
export const tableSchema = createTableSchema({
level: col
.enum(LEVELS)
.label("Level")
.filterable("checkbox", {
options: LEVELS.map((l) => ({ label: l, value: l })),
})
.defaultOpen()
.size(27),
date: col
.timestamp()
.label("Date")
.display("timestamp")
.sortable()
.defaultOpen(),
latency: col
.number()
.label("Latency")
.display("number", { unit: "ms" })
.filterable("slider"),
});
One definition. Four generators derive columns, filter fields, filter schema, and sheet fields automatically. Five files collapsed into one table-schema.tsx.
This became the foundation for everything that followed — the builder, the Drizzle integration, the registry all depend on it.
It was also only possible to build because of all the extra work done before. It's fine to copy-paste things and not extract too early — until you see the pattern and can actually optimize for it.
The schema builder
If the schema can be generated from a definition, why not generate it from raw data?
A builder where you paste JSON (or upload a CSV) and instantly get a working, filterable table. No column definitions. No config. Just data in, table out.
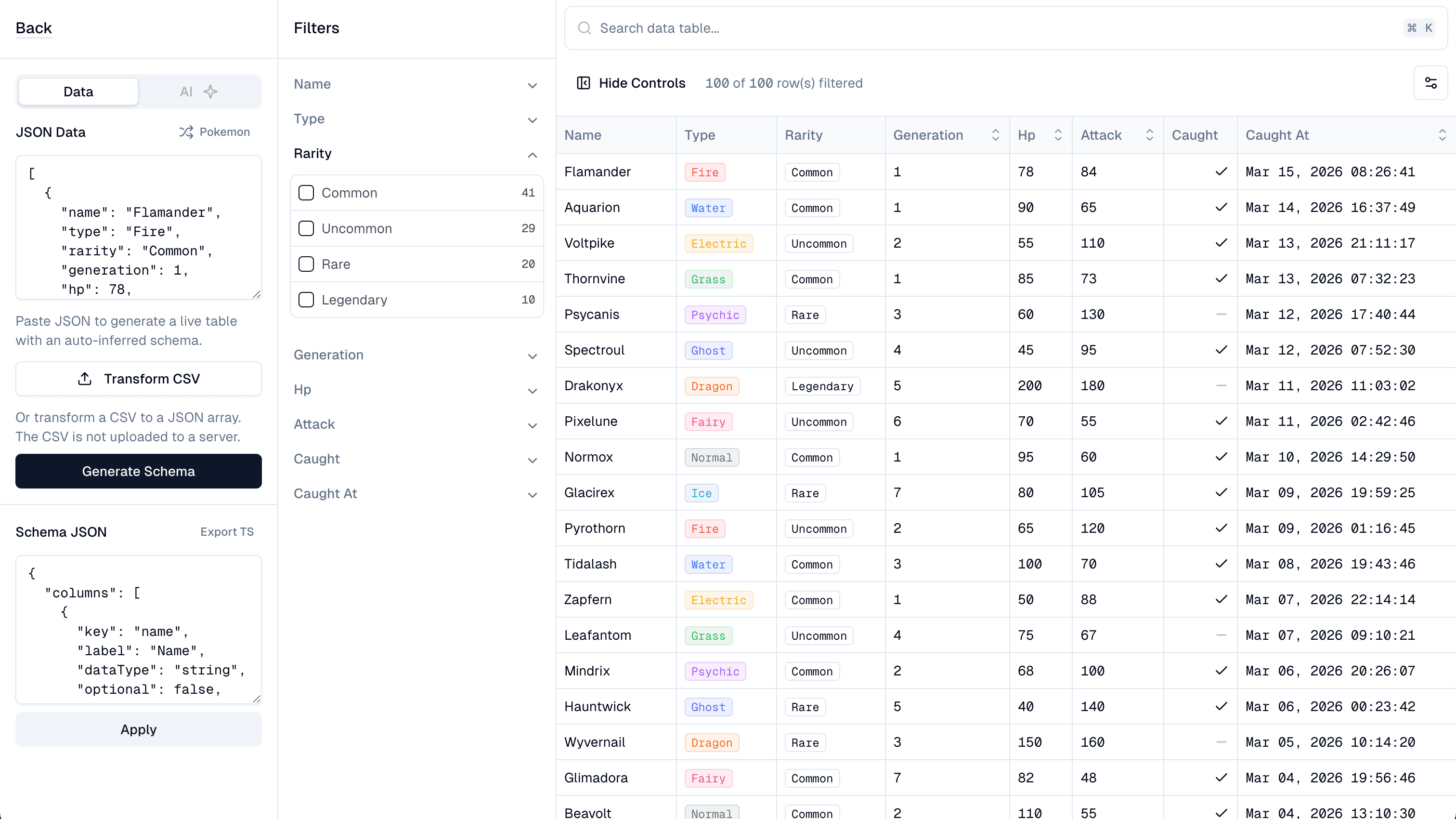
The components aren't fully customizable in the builder (serialization constraints), but it helps you get started and understand how schema changes affect the data table.
The inference engine detects types and applies domain heuristics — keys with "latency" get millisecond units, "id" columns get monospace display, trace IDs are auto-hidden. We ship presets for common patterns like timestamps, durations, and log levels. Contributions welcome — the more opinionated, well-built presets we have, the better the out-of-the-box experience gets for specific use cases.
The preview uses the same infinite-scroll architecture as the real thing — what you see in the builder is exactly what you'll ship.
Drizzle ORM: a real database with real data
A client-side demo only takes you so far. People need to see this working with a real database, real data, growing over time.
We built a full Drizzle ORM integration connected to a Supabase PostgreSQL database.
A Vercel cron job runs every 10 minutes, generating realistic HTTP request logs — randomized timing metrics, status codes, multiple regions with latency multipliers. The data accumulates over time, so the demo always has fresh, realistic data to filter through — and it supports live mode (just time it right, the cron runs every 10 minutes).
The /drizzle route shows it all working together: infinite scroll with cursor-based pagination, faceted search with live mode, nuqs URL state so filters are shareable, and time-bucketed charts via PostgreSQL's date_bin().
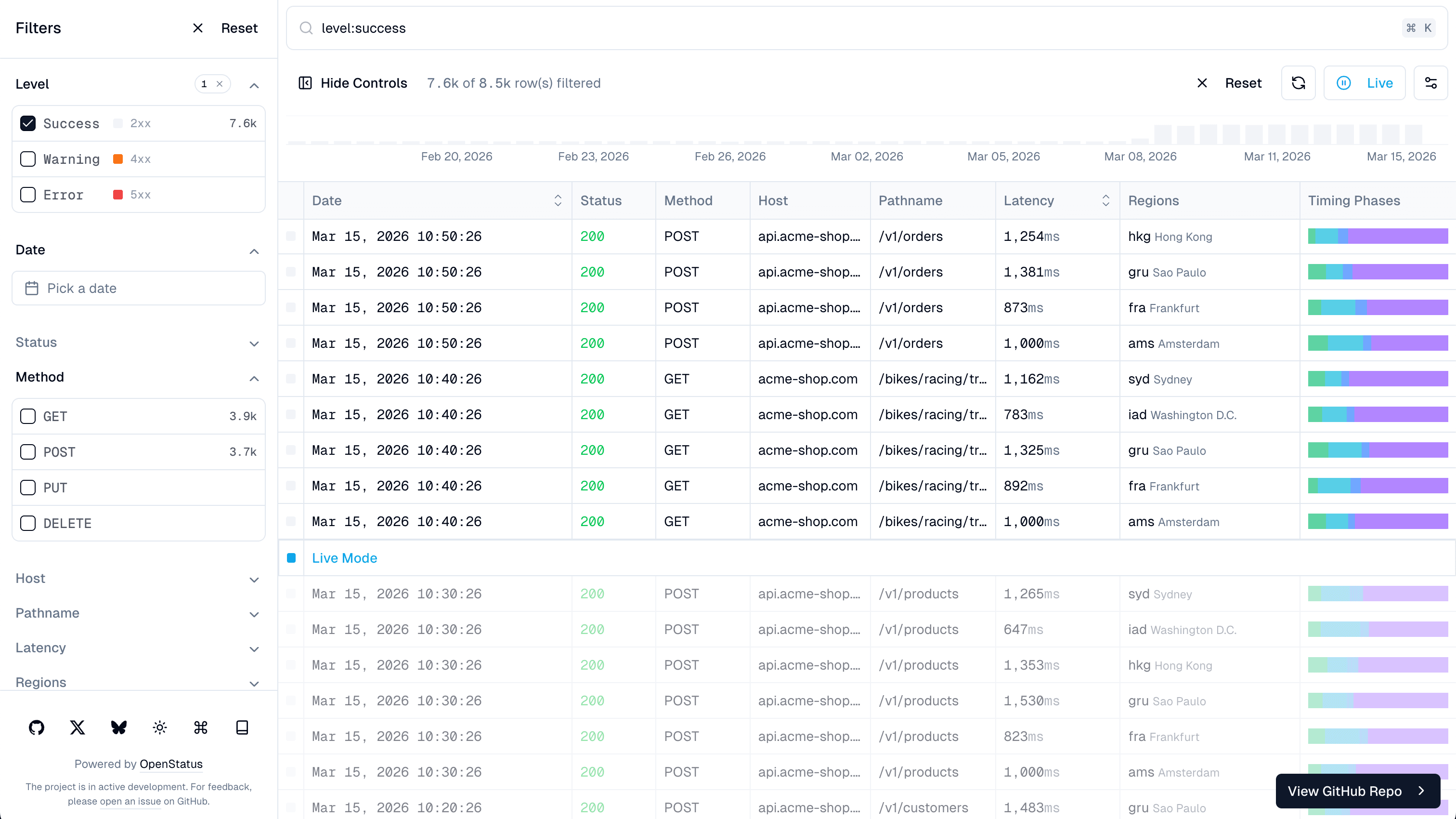
This is the kind of example that actually helps people adopt a library. Not "here's a static demo" — here's a production-like setup with a real database, real data pipeline, and all the pieces wired together.
Tests. Lots of tests.
Writing good tests is cheap nowadays. Just do it. Thank me later.
39 test files covering the table schema, store adapters, builder, Drizzle ORM (including a dedicated SQL injection suite), and utilities. Everything from column builder validation to '; DROP TABLE logs; --.
CI runs against a real PostgreSQL container — migrations, seed data, then tests. No mocks for the database layer. We want this production-ready, so making sure test coverage is solid and tests are green is non-negotiable.
Distribution killer: shadcn registry + agent skill
A GitHub issue (#39) put it plainly: "Can you please provide it as a package, so that it could easily be installed and managed?" Another (#14) asked for a Vite example, which would've meant restructuring into a monorepo.
The shadcn registry solves the distribution problem. Adopting it required migrating to Tailwind v4 first (which was long overdue!) — the registry blocks declare CSS variables using @theme inline syntax, so v4 was a prerequisite. Then we created a registry.json with 9 installable blocks:
npx shadcn@latest add https://data-table.openstatus.dev/r/data-table.json
One command. Dependencies resolved. CSS variables injected. Path aliases rewritten. Install just the core, or add Drizzle helpers, command palette, zustand adapter — whatever you need.
Then there's the agent skill.
Think about what a CLI installer does: it asks you questions ("TypeScript?", "Which state manager?", "Do you use Drizzle?"), then generates files based on your answers. It's a decision tree pretending to be a conversation.
An agent skill is an actual conversation. Install it with:
npx skills add https://github.com/openstatushq/data-table-filters --skill data-table-filters
When someone opens their AI coding tool and says "add a filterable data table", the skill activates.
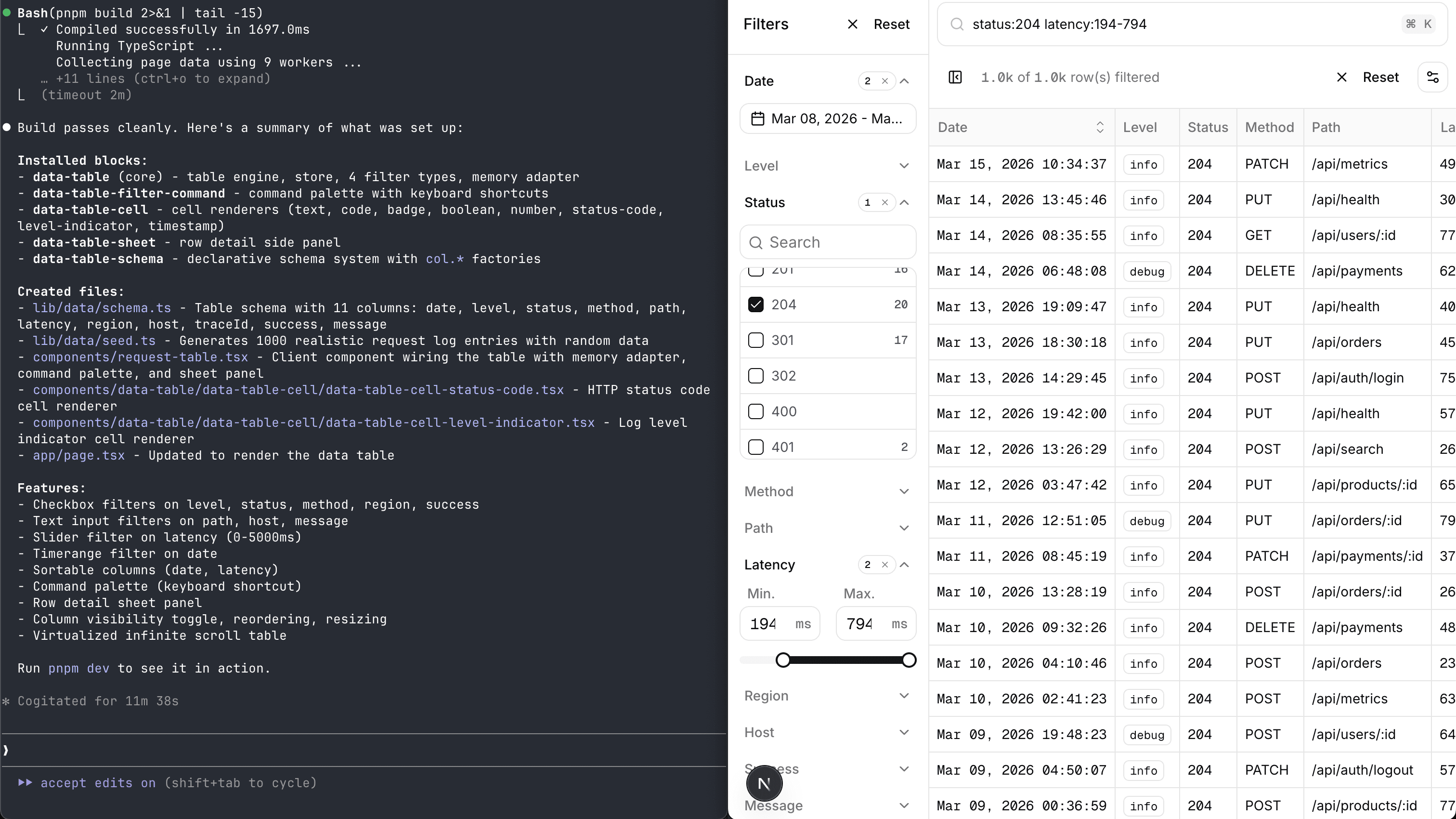
It understands the project, installs the right blocks, generates a schema from the data model, wires up the state adapter, and configures the database integration — if you ask for it. Start minimal and expand to your use case.
We also rewrote all the docs from scratch. Not glamorous work — but when an AI reads your docs to install your library, doc quality directly affects agent quality. Better docs, better agent.
Where this is going
We keep improving data-table-filters to make it the fastest way to spin up large, production-ready dataset views for logs and beyond.
It's not a library. It's a playbook.
The combination of shadcn registries and agent skills is a really good distribution model for frontend libraries. You don't publish a package with a fixed API. You ship composable code blocks, matching your design system, that an AI understands how to assemble.
Not "install this package and read the docs." More like "tell your AI what you need and it builds it from well-structured, composable pieces."
Nobody should hand-code a data table anymore.
The full project is open source at data-table-filters. Try the builder at data-table.openstatus.dev/builder. Or just open your favorite chat interface, install the agent skill, and say "add a filterable data table" — the skill will take it from there.