A year of openstatus: what we learned
May 29, 2026 | by Maximilian Kaske | [company]

A year ago we published Product Strategy - A Reality Check. It was an honest post to write: ~7,000 GitHub stars, no clear answer on what to charge for, a "self-hosted" story that didn't actually work, and a head full of features we kept not shipping (RUM, on-call, incident management).
This post is a year's receipt. What we shipped between then and now, what we killed, what we got wrong, and the people who helped us see what we couldn't. It's not a highlight reel. It's the version we'd want to re-read in a year and either nod at or wince at. Less polished essay, more honest digest: shippable as a talk, a post, or just a conversation we wanted to write down.
Who's this post for? Primarily for us, a checkpoint for next year. But we figured it could live here in the blog, so we get to share it with you too.
Spoiler from the original Reality Check still applies: it's been hard, really hard.
The story in one paragraph
12 months ago we partnered with Emily Omier to grill us on positioning. We killed the ideas of RUM, on-call, and incident management (we never actually shipped them, they just took up space in our heads), dropped synthetic-monitoring-as-headline, partnered with Alex on design, rebuilt the dashboard, rebuilt the status page, doubled down on MDX-driven SEO, decoupled our monorepo, migrated our entire API to ConnectRPC, and went deep on AI (skills repo, MCP server, CLI, chat assistant, Slack agent). In March 2026 we brought in Shane O'Connor to help us on distribution. We started posting on LinkedIn for real, stood up a subreddit, automated LinkedIn connections to widen our network reach, rechecked our ICP, and updated the homepage hero around compliance. We also welcomed Colin, our first intern, finally not a two-person team. And the community on Slack and Discord became one of our favourite parts of the work. Today: focused product, ~1M Google impressions in the last 3 months, a real distribution motion, a defensible wedge. This is the honest version of how we got here, including what didn't work.
Section 1: Where we were
March 2025. We didn't feel particularly unique. We were chasing stars instead of talking to the people actually using the product. We were lost.
For a visual receipt: v1.openstatus.dev. The old site is still live, frozen, as a snapshot of where we were (dated from early Dec. 2025). Useful both as a before/after and as a reminder of how easy it is to drift if you're not paying attention.
Today, May 2026: same product category, same two founders, plus Colin, our first intern. Different company underneath. There's one chart that frames the whole year, but we've saved it for the numbers section, where it belongs.
Section 2: The shift
The mental-model change, in two parts.
What we admitted to ourselves
- Self-hosting was hard, even for us. Marketing "open source" was partly cope.
- Our marketing page listed features, not problems. We were proud of the wrong things.
- Synthetic monitoring is broken, and we're not the ones to fix it. We had an opinion. We still have it. But the market is brutal, and we can't out-spend Datadog or BetterStack on this. So we stuck with uptime monitoring, which fits cleanly with our compliance + status-page story. Picking a fight you can win is a feature.
- We had no focus. We were yolo-coding, trying the latest frameworks, daydreaming about RUM, on-call, incident management.
- We weren't dogfooding our own public API. Internally we used tRPC; publicly, REST. Every endpoint defined twice. Every bug fix risked inconsistency. Half the velocity, double the surface area.
- We weren't really in the community. We had a Discord and a Slack, but we treated them like a support overflow channel, not the room we lived in. It's still hard, honestly, we're devs, and our default is to disappear into the code, but we're getting better at it.
What we did about it
- Killed the idea of RUM, on-call, and incident management. We never actually shipped any of these. They just lived rent-free in our heads. Letting them go (for now, they're still on the long-term horizon as the product line expands) freed up a lot of focus. Also dropped "synthetic monitoring as the headline" and "let's try this new framework just for fun."
- Partnered with Emily Omier to grill us until the actual product fell out. (Outside voice #1: positioning.)
- Partnered with Alex: a design partner who shared the nerdy obsession with details. Gave us Figma mocks that became the new dashboard and the new status page. The opinionated choices (monospace type, dense, deliberate layouts) made the product stand out, and they land precisely because our main users are devs who recognize the references. (Outside voice #2: design.)
- Started collaborating with Shane O'Connor in March 2026 on distribution. Got us actually posting on LinkedIn, set up automated connection requests so we could reach founders and like-minded people in the space, rechecked our ICP from scratch, pushed us to update the homepage hero around compliance, and stood up
r/openstatuswhere we post and comment on adjacent threads. We also recorded our very first podcast in this stretch, talking publicly about the work, not just shipping it. (Outside voice #3: distribution.) - Welcomed Colin as our first intern. Three is a very different team than two. Things we'd been postponing because nobody had the time finally moved.
- Showed up in the community. Slack and Discord stopped being a ticket queue and became the room. We reply fast, we ship fast, and users tell us, repeatedly and unprompted, that this is the thing they appreciate most. Power contributors like Moulik took it a step further than feedback: he's been hugely supportive and shipped features like status-page i18n or importers.
- Released a self-hosted version (so the OSS story stops being a half-truth, unblocked partly by Tinybird shipping their own Docker release).
- Decoupled the monorepo: split web, dashboard, status-page, and a shared
@openstatus/servicespackage. A Linear issue we'd been staring at for a year, finally done. - Migrated the API to ConnectRPC: one schema, type-safe internally, curl-able publicly, with generated clients that actually work in Go and Rust.
- Rewrote the dashboard, the status page, the landing. All on purpose, all in sequence.
The line: We thought our problem was technical. It was strategic. We needed someone outside the team to ask the questions we were avoiding. Emily named the product. Alex shaped the look. Shane named the distribution problem we'd been dodging.
Section 3: The pillars
The funnel frame. This is the spine. It came out of the year-in-review post, and it explains the chart.
Users search for a Status Page → they see it's Open Source → they stay for the bundled Uptime Monitoring.
Each pillar serves one part of that funnel. They're not parallel features. They're a causal chain. Below them sits a fifth pillar (architecture/AI) that we used to think was infrastructure and now think is product.
| Funnel stage | Pillar | What shipped |
|---|---|---|
| 1. Search → find us | Landing / SEO | MDX engine, free tools, compares, guides, opinion pieces |
| 2. See it's open source | OSS credibility | Self-hosted release, skills repo, CLI, MCP server, Terraform provider |
| 3. Stay for the dashboard | Dashboard | Full rebuild, Linear-inspired DX, decoupled app |
| 4. Communicate during fires | Status Page | Full rebuild, Theme Explorer, importers, i18n, components, embeds |
| 0. The substrate underneath | Architecture & AI | services consolidation, ConnectRPC, Slack agent, Chat Assistant, audit log |
Pillar 1: Landing / SEO
The boring one. The one that worked.
Before: Pretty landing, thin content. Listed features, not problems.
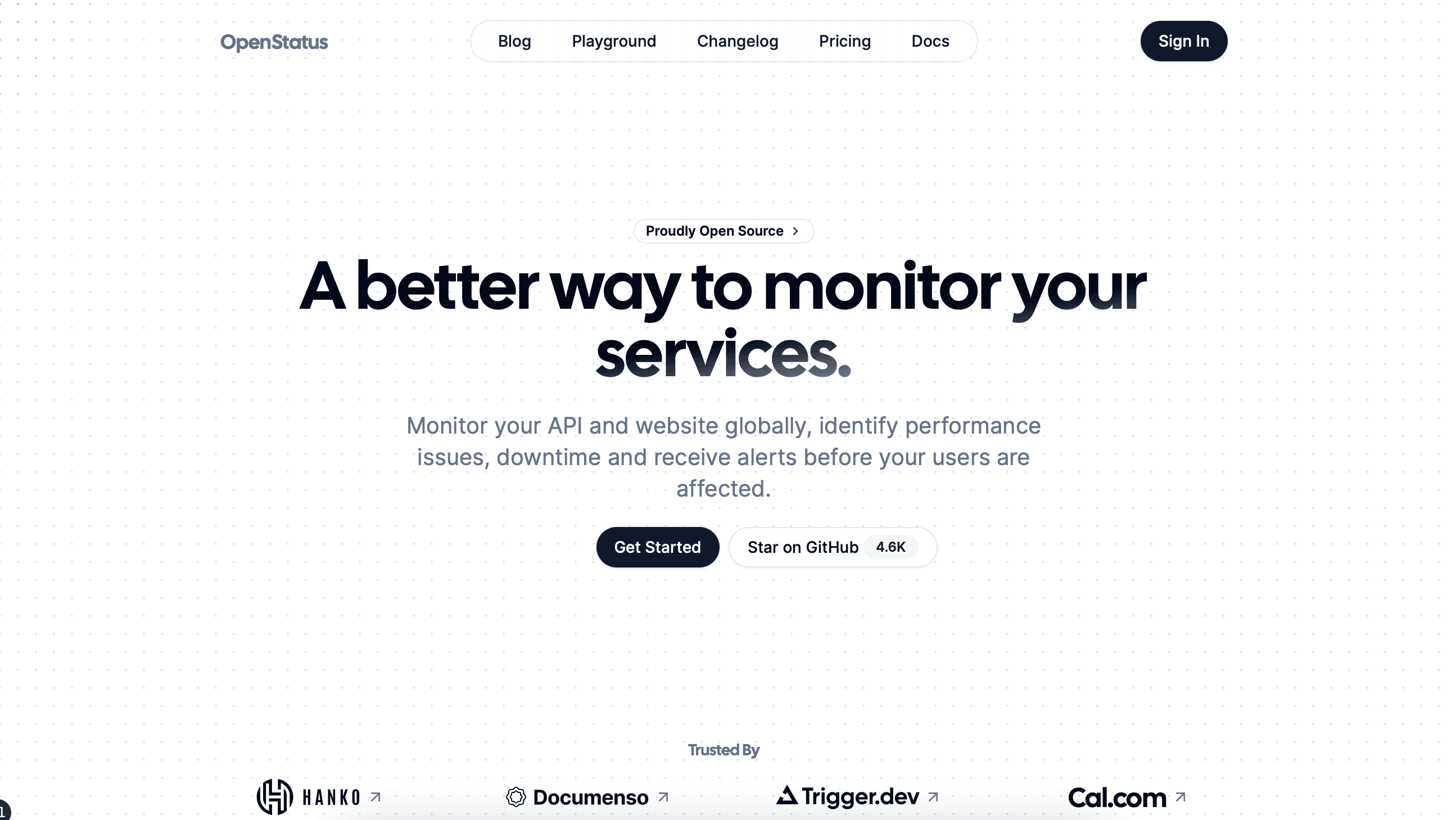
Shipped:
- PlanetScale-style MDX-first content engine, fast to publish, easy to ship
- Compares (Atlassian, BetterStack, Checkly, Instatus, incident.io, statusio, Uptime Kuma)
- Guides and use-cases (Status Pages for Startups, for API Providers, for Compliance, for Crypto, for Reducing Support Tickets, for Enterprise Sales): one page per ICP profile we care about, not a content firehose
- Free tools that rank: cURL Builder, Global Speed Checker, SLA Calculator, Theme Explorer, shadcn component registry, and the GSC numbers back it up (
/play/curlis our #2 click driver, behind only the homepage) - Opinion pieces with a point of view: Status Pages Are Politics, Public Postmortem Is Underrated Marketing, Why Uptime Percentage Is Misleading
- SEO is a discipline, not a publishing volume. We don't spam content. We ship a dedicated page per customer profile and keep it tight. Every guide carries proper JSON-LD (How-To and FAQ schema where it fits).
Result: ~650K Google impressions over 16 months (Oct 2023 – Feb 2025) → ~1M impressions and ~19k clicks in the last 3 months alone (Feb 16 – May 17, 2026, per GSC). From ~40K impressions/month to ~333K/month, a ~8× jump in rate.
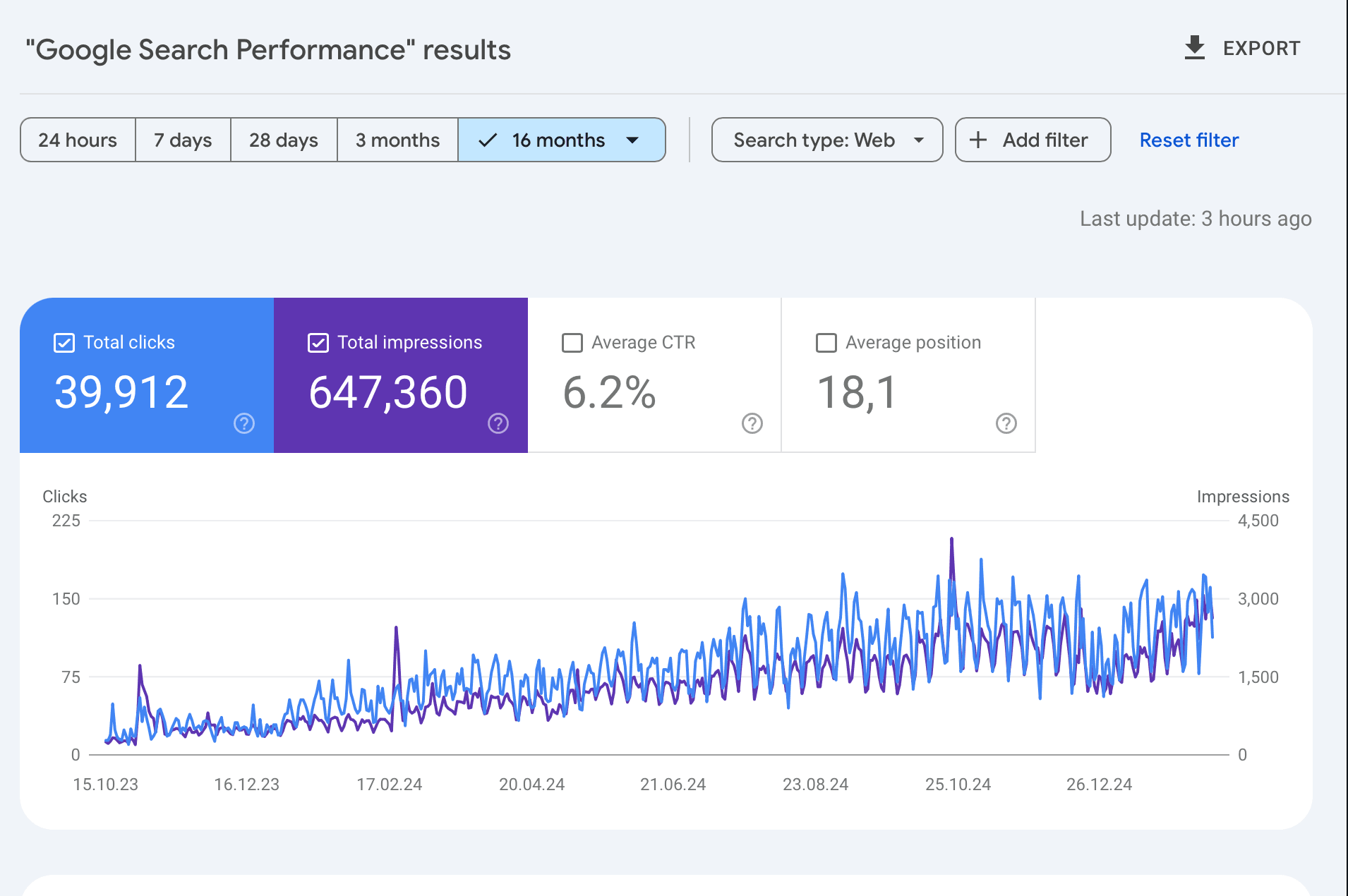
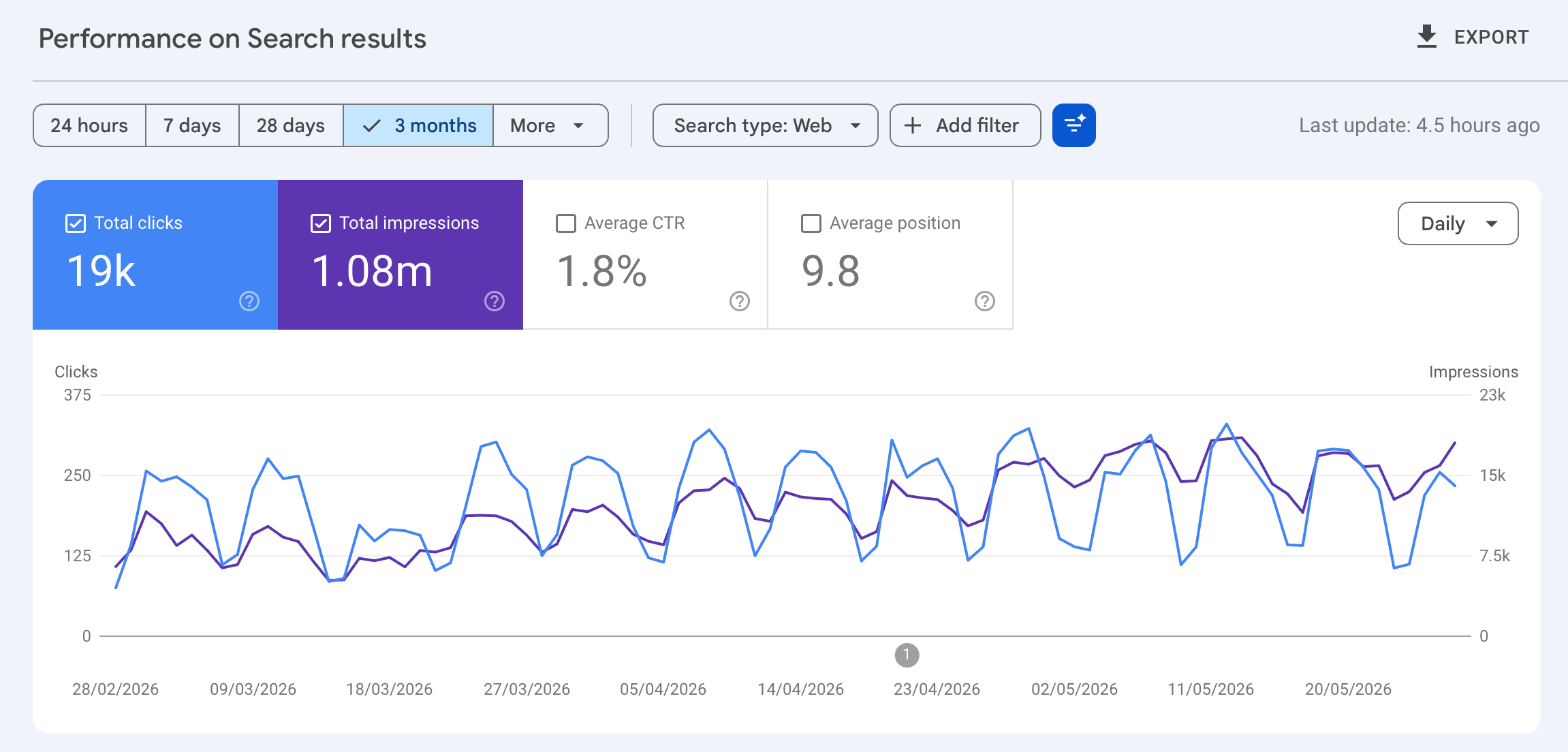
The lesson: We built free tools because they ranked. They rank because they're useful. They're useful because we'd use them ourselves. And opinion pieces beat feature pages. Status Pages Are Politics did more for positioning than any landing copy we wrote.
Pillar 2: OSS credibility
The half-truth we fixed.
Before: The Reality Check post put it bluntly: "We're not great at maintaining our self-hosted product." The badge said open source; the experience said otherwise.
Shipped:
- Actual self-hosted version: the proper all-in-one release shipped in December 2025, finally unblocked by Tinybird Local landing. Before that we technically had a self-hosted path; in practice it was held together with prayer.
- Skills repo:
github.com/openstatusHQ/skills. Open-source AI skills for incident communication, status page theming, CLI, status page configuration - MCP server at
api.openstatus.dev/mcp. Same registry as the chat UI, same scopes - CLI built for humans and agents (TTY detection, wizard fallback for humans,
--jsonand structured errors for machines) - Terraform provider: full GitOps for monitors, pages, notifications
- The Reality Check post itself: writing down what was broken, in public
The community side of OSS: Feature requests turn into PRs. Bug reports turn into same-day fixes. People drop into Discord to ask a setup question and stick around to answer the next one. For an open-source project that's the whole point: the code is open, and so is the room around it.
Why this pillar matters for the funnel: without a real self-hosted option, users find us → see "OSS" → spot the half-truth → leave. With it, they trust the project and decide they want the hosted version anyway.
Pillar 3: Dashboard
Before: Outdated, noisy, still built on the very first hype. People stayed despite the dashboard, not because of it.
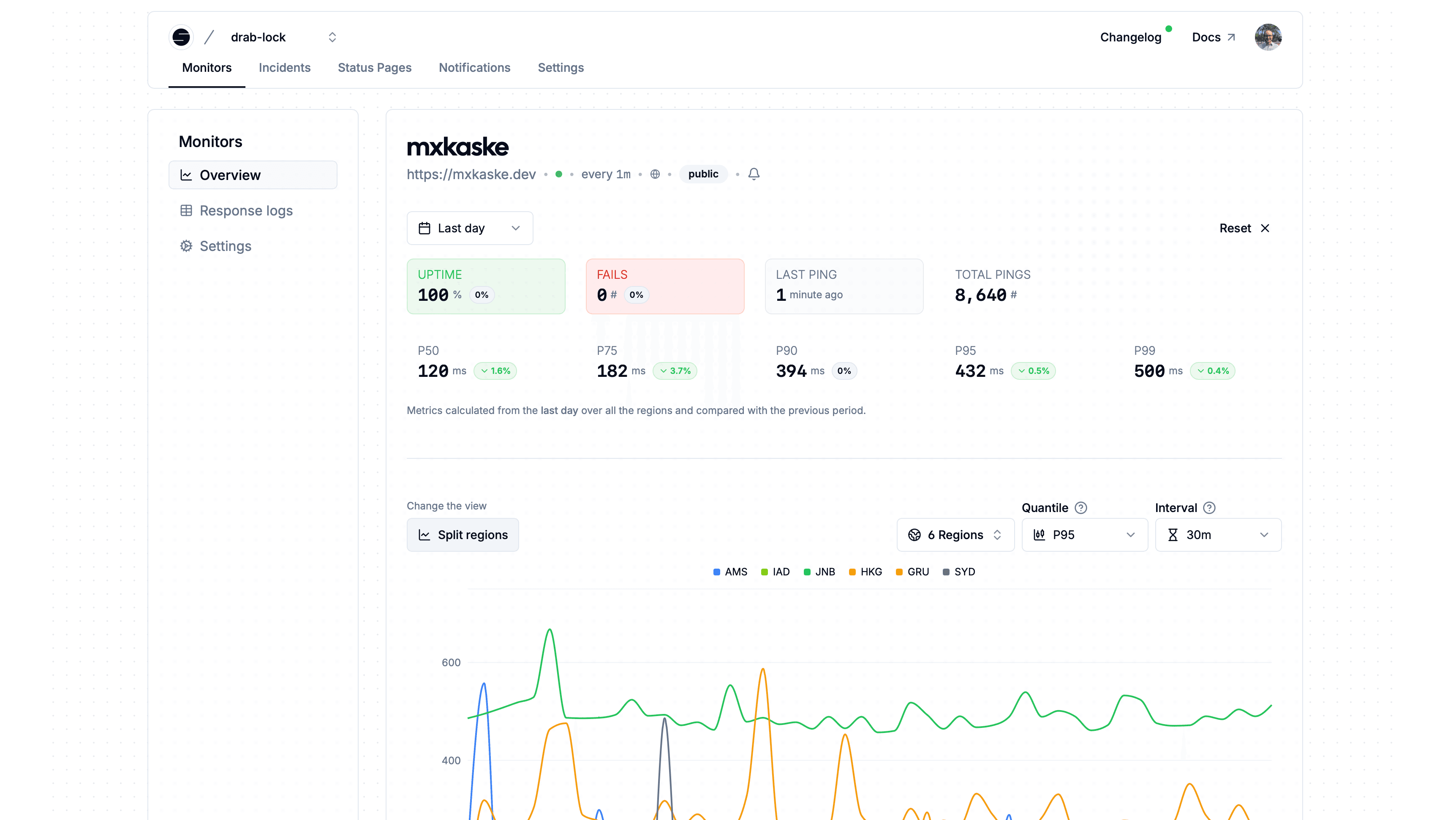
Shipped: Full rebuild (blog: We Are So Back) on the second anniversary of openstatus. Tinybird-inspired sidebar navigation. Right-hand context drawer borrowed from Axiom. Cleaner data viz, with timing-phase charts, uptime bars, degraded overview cards, built on the data we'd been collecting in Tinybird and never displaying.
Why it mattered: existing-customer retention. Activation got cleaner. Status-page customers who'd never explored uptime monitoring started using it. The third step of the funnel stopped being embarrassing.
The line we keep: The products you use, inspire the products you build. Linear, Tinybird, Axiom, Resend,... Stand on the shoulders of taste you trust.
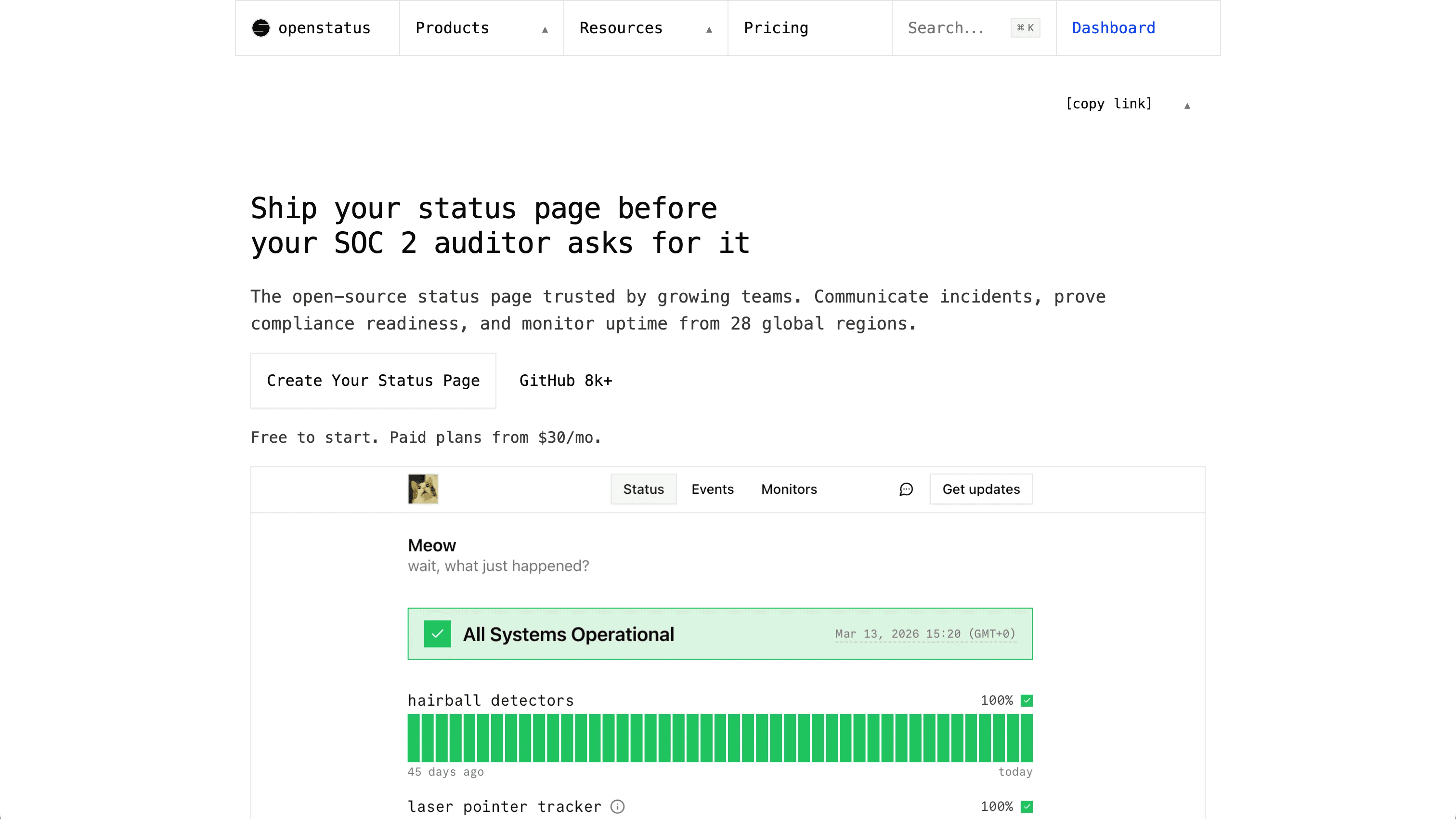
Pillar 4: Status Page
The pillar that became the strategy.
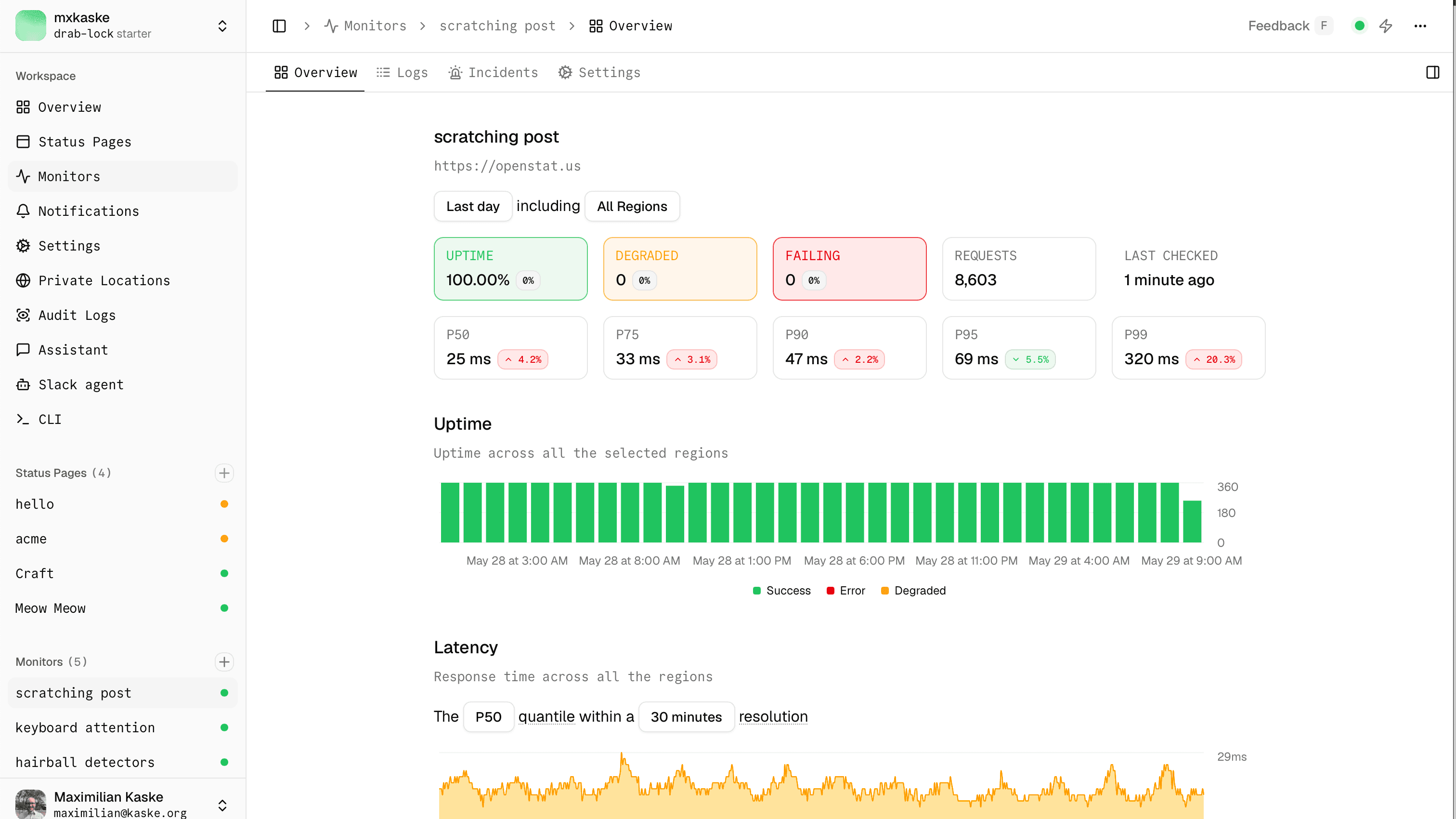
Before: Status page was "the thing at the end of monitoring." Outdated. Hard to make yours.
Shipped:
- Full redesign + Theme Explorer + theme builder (Squared default, Rounded legacy, Supabase, GitHub high-contrast, and contributions welcome). See Introducing the Status Page Theme Explorer
- Status page is now a standalone app, fully separated from web
- Status Page Importer for Atlassian Statuspage, Better Stack, and Instatus. Full migration in a few clicks
- Add-ons that surprise: i18n, password-protected pages, IP restriction, email auth, white-label, embeddable iframe, JSON view, status page badge v2, component groups, component subscriptions, Slack feed subscribe, search-engine indexing controls
The strategic shift:
Users search for a Status Page → they see it's Open Source → they stay for the bundled Uptime Monitoring. The entry point isn't the monitoring; it's the Status Page.
That insight reorganized how we think about the product. The 2026 plan: "Stripe for Incidents." ChatOps-first, API-first, primitives over rigid workflow. Slack and Discord apps. Deep integrations. Move upstream toward incident management later, not by building it ourselves but by being the platform others build on.
Pillar 5: Architecture & AI (the substrate)
We used to file this as plumbing. It's product.
Architecture work we did "before" we shipped anything new:
- Split the monorepo into web, dashboard, status-page, and a shared services package.
- Built
@openstatus/servicesas the single chokepoint for every mutating database operation. REST calls into it. tRPC calls into it. The Slack agent calls into it. The chat assistant calls into it. Three CRUDs collapsed into one. - Migrated tRPC + zod-openapi → ConnectRPC. One schema, type-safe internally, curl-able publicly. Halved our endpoint surface area; generated clients we actually trust.
- Audit log that covers all three surfaces: dashboard, API, agent. "An audit log that only logs some of the writes isn't an audit log. It's vibes."
- API key scopes (read/write): the same guard gates the V1 API, the MCP server, and the chat UI. Read-only keys don't 403 on write tools; the write tools don't exist in
tools/list.
AI surface area we shipped:
- Skills repo: open-source AI skills you
npx skills addinto your agent - MCP server: the dashboard's own tools, exposed for Claude Desktop, Claude Code, Cursor, ChatGPT, anything that speaks MCP
- CLI built for humans + agents: TTY-detection,
--json, structured errors, wizard fallback. Same tool, two audiences. - Slack agent:
@openstatusin a thread, describe the fire, approve the diff, status page updated. No slash commands. Human-in-the-loop on every write. - Chat Assistant at
/chat: same tool registry as MCP; rich-vs-raw tool cards; ⌘↵ to approve, Esc to cancel; render tool results as the same React tables the dashboard uses everywhere else.
The framing we landed on:
ClickOps · ChatOps · GitOps. The trifecta is complete.
Dashboard for clickers, chat for talkers, Terraform for committers. Same services layer under all three. Same audit log. Same scopes.
The honest line: We're not adding AI to look modern. We're using it because the actual workflow demands it. Status pages are a place where "don't make me leave my terminal" is the whole product.
Section 4: The outbound motion (added March 2026)
The pillars above are the inbound funnel: how strangers find us. By Q1 2026 it was clear we'd built a system that pulled people in but didn't reach out to anyone. As devs, we'd rather ship than DM. Shane changed that, not by handing us a full GTM operation, but by getting us to actually show up.
This is the newest part of the story (~2 months old at time of writing). Too early for a verdict. Worth writing down anyway.
What we actually did
- Started posting on LinkedIn for real. From near-zero to a regular cadence. Both founders, multiple posts a week. The bar wasn't viral; the bar was present.
- Stood up
r/openstatus. A place to post launches and updates, and, more importantly, somewhere we comment on adjacent threads about status pages, incident comms, and uptime tooling. - Automated LinkedIn connection requests to connect with founders and like-minded people in the space. The goal isn't a pitch. It's expanding the network, so when we publish, comment, or DM, we're already in the same room as the people building things we care about.
- Recorded our first podcast. Talking about the work, not just shipping it. Long-form, in our own voice, on the record. It's a different muscle than writing, and it's good for us to flex it. Keeping a cadence is tough, but we're about to record the second one.
- Rechecked our ICP from scratch. Not the deck-deep version: the who is actually paying us, what do they share, where do they hurt version. The answer wasn't "enterprises" and it wasn't "hobbyists." It was small/mid teams with API surface area and a compliance shadow growing over them.
- Updated the homepage hero around compliance. "Open source uptime monitoring and status page" had been our headline for years: accurate, dev-aimed, but not the question the buyer was asking. The new hero leads with the compliance story.
- Added more use-case pages. Concrete, specific, customer-shaped, not "monitoring for everyone."
What changed because of it
- LinkedIn went from a graveyard to a channel. Conversations started in DMs that wouldn't have started anywhere else.
- The homepage talks to the buyer, not the dev who already loves us.
- The ICP recheck quietly reorganized everything we say about the product. Even copy that didn't change reads differently when you know who you're writing for.
Two months is too short for a verdict. The fact that we're showing up for the work at all is the change.
Section 5: A few numbers for comparison
We're wary of bragging with numbers we made up ourselves. So we lean on the ones we don't control: GitHub stars, Google Search Console impressions, follower counts pulled straight from each platform. Not perfect, but at least nobody at openstatus gets to put a thumb on the scale.
Here they are, before and after.
| Metric | Mar 2025 | May 2026 | Change |
|---|---|---|---|
| GitHub stars | ~7,000 | ~8,700 | +24% |
| GitHub followers | 128 | 201 | +57% |
| Google impressions (rolling) | ~650K over 16 mo | ~1M over 3 mo | ~8× rate |
And the community across channels (useful for us to look at, so probably useful to share):
| Channel | Mar 2025 | May 2026 |
|---|---|---|
| 197 | 362 | |
| Bluesky | 746 | 904 |
| X / Twitter | 962 | 1,406 |
| Discord | 359 | 392 |
| YouTube | 11 | 21 |
The chart that frames the whole year. Plot paid subscriptions from Jul 2023 → May 2026 and there's one clear elbow: August 2025. Two things happened that month. We published Product Strategy - A Reality Check on July 31, and we shipped We Are So Back on August 3, the new-dashboard launch that kicked off the entire monorepo rollup (web / dashboard / status-page split). Words on the page and an app under the hood, in the same week. We can't prove the causation, but that's the month everything started compounding.
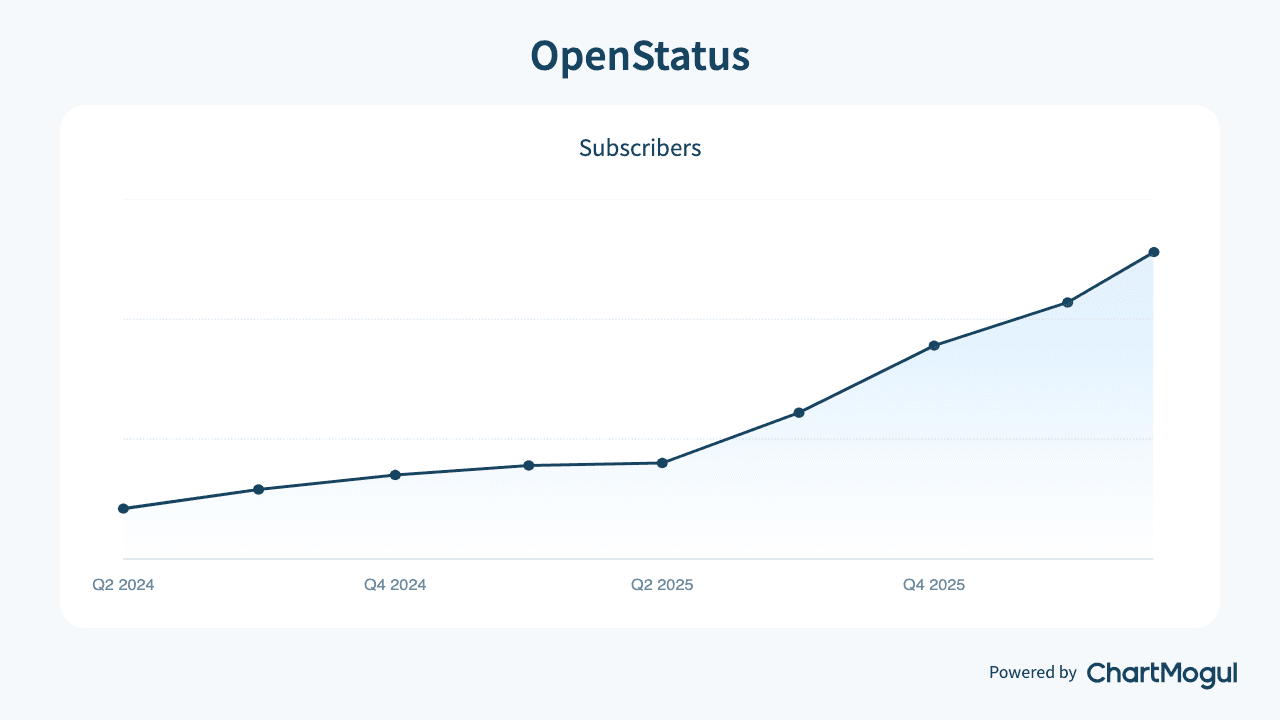
The point of the table: GitHub stars grew by about a quarter. The work underneath grew at a very different rate. The vanity metric and the metric we actually care about have decoupled. Stop optimizing the wrong one.
Other moments worth dropping in:
- An acquisition conversation in 2025. Strong offer, fantastic team. We said no. We aren't done yet. We chose to stay independent and keep building.
- Product Hunt, October 2025. Flo Merian launched us with us getting surprised on a Saturday. We finished #2 of the day, behind Anthropic Skills. The conversion to actual users was effectively zero, and we didn't even make the newsletter. We wrote the whole thing up in Our Product Hunt Launch: The Brutal Reality. Lesson: Product Hunt isn't a marketing strategy in 2026. Also, sometimes the YOLO is fine.
- The first openstatus retreat: Kochel am See, Bavarian beer, e-bikes, Kaiserschmarrn. It's also where we wrote the 2026 roadmap together. Two-person team doesn't mean two people in two cities forever.
Section 6: Lessons
The actual learnings, year over year. Some of these are old hats; the value is in the receipts now.
1. You cannot self-diagnose your positioning. Or your distribution. Bring someone in to do both.
From the Reality Check post: "If you know what makes you special, you can lean into it." We didn't know, until Emily made us. A year later we made the same move on distribution: brought Shane in to shape the messaging, run the LinkedIn motion, and make us post. Same pattern, different bottleneck. The thing you can't see is the thing costing you the most.
2. Shipping less is a feature.
From the Reality Check post: "We have reduced the number of new features shipped over the last months, on purpose." Focus by subtraction. We killed RUM, on-call ambitions, incident management ambitions, synthetic-as-headline. The product got clearer every time we killed something.
This matters more in the age of AI, not less. When you can generate a feature, a UI, or a whole subsystem in an afternoon, the constraint stops being can we build it and becomes should we. It's never been easier to bloat the codebase and the interface with things nobody asked for. Subtraction is the discipline that no longer comes for free.
3. Consolidate before you add.
The biggest unlock of 2025 wasn't a feature. It was a refactor we'd been postponing for a year. Splitting apps. Pulling CRUD into one package. Migrating two APIs into one ConnectRPC schema. "Sometimes you have to take a few steps back to take more steps forward." Every feature shipped after the refactor took half as long.
4. Be honest about the gap between your OSS story and your reality.
If you market "open source" but your self-host story is held together with duct tape, the people who care most will notice first. We let that gap sit for too long. Closing it (actually shipping a self-hosted release, writing down what was broken in public) did more for trust than any feature.
5. The vanity metric and the metric you actually care about decouple.
Stars grew by about a quarter; the work underneath grew at a very different rate. At some point the community-love metric and the metric you actually care about stop moving together. Notice when. Stop optimizing the wrong one.
6. Not doing the outreach is the biggest trap, and you won't fix it alone.
We're devs. We're born to build, not to DM people on LinkedIn. The trap is staying in the "just one more feature and the rest will sort itself out" loop forever. We sat in that loop for years. What broke us out of it wasn't willpower. It was collaborating with Shane to set up the motion, point us at the right lists, and force a posting cadence. The founder still has to do the talking. But you probably can't be the one to schedule it, structure it, or hold yourself accountable to it.
6a. Recheck your ICP every now and then. The honest version, not the deck version.
Working with Shane forced us to redo the who is actually paying us, what do they share, where do they hurt exercise. The answer wasn't "enterprises" and it wasn't "hobbyists." It was small/mid teams with API surface area and a compliance shadow growing over them. That single redefinition reorganized the homepage hero, the use-case pages, and how we talk in DMs. The ICP isn't a slide; it's a lens, and it goes out of focus faster than you think.
6b. Showing up in the community is undervalued.
We have a Slack and a Discord. Used to feel like a chore; now feels like the best part of the week. Replying fast and shipping fixes fast is, apparently, rare enough that users tell us about it, repeatedly, unprompted. It's also one of the few advantages a tiny team has over a big competitor. Don't outsource it. Don't queue it. Don't treat it like support. Hang out there.
7. Design for the agent from day one.
--json, structured errors, deterministic flags, MCP from the start, write-tools that pause for human approval, audit-logs that cover the agent same as humans. These aren't bolt-ons; they're the foundation. Our Slack agent and chat assistant ship feature-complete in part because the CLI, the API, and the services layer were already built right.
8. Opinion content beats feature content.
Status Pages Are Politics did more for positioning than any "features" page. Nobody should hand-code a data table in 2026 drove more conversation than the changelog around it. Our Product Hunt Launch: The Brutal Reality was a stronger founder signal than any positive case study. A take with skin in it travels further than a list of capabilities.
8a. Treat SEO like a discipline. Check the numbers. Rewrite, don't restack.
We look at GSC regularly (not religiously every week, but often enough to catch a page slipping). We don't publish a changelog for every new improvement. We publish a page per ICP profile, and then we rewrite the ones that lose position instead of stacking new posts on top. Proper JSON-LD (How-To, FAQ) where it fits. Topical clusters that link to each other. The boring stuff.
9. Distribution > novelty.
Free tools that rank. Importers from your competitors. Notification channels into wherever the user already lives: Slack, Discord, Telegram, WhatsApp, Google Chat, Teams, ntfy (see the changelog). Migration friction is a moat; we tore it down on our side and built it on theirs.
10. Stand on the shoulders of taste you trust.
shadcn for components. Tinybird for analytics. Linear for navigation. Axiom for context panes. Supabase for opinionated polish. The products you use, inspire the products you build. Don't reinvent taste. Borrow it, attribute it, and spend your originality on the actual product.
11. Write things down, even badly, and you'll thank yourself later.
We're honestly still not great at narrating what's going wrong in real-time. But every "Reality Check", every "Vision 2025", every year-in-review post, every retro like this one: they pile up into something we can actually look back on. The act of writing it down isn't always the magic; the archive is. A year from now we'll re-read this post and either nod or wince. Either way, the next move gets clearer. And, if it's at all useful to you, we share it as we go.
12. Status-page-first wasn't obvious until we measured it.
We assumed users came for monitoring. They came for the status page and stayed for the monitoring: the funnel insight we wrote up in the 2026 roadmap post. The entry point isn't always the product you're proudest of. Look at the funnel, not the spec sheet.
13. The hero you talk to on the homepage isn't always the user you think.
For years our headline was some flavour of "open-source uptime monitoring and status page." Even v1.openstatus.dev was an iteration of that ("Showcase your uptime with a status page"). All true, all accurate, all aimed at the developer who was already going to like us. The new hero leads with the compliance story, because that's the question on the other side of the developer's desk. The dev still adopts the tool, but the headline needs to also answer the question their team lead is being asked. Write to that reader.
Closing thought
Steal from the Reality Check post:
What Emily really gave us isn't a positioning canvas. It's a method. When you're stuck, find someone who'll ask the questions you're avoiding.
That's the through-line. 12 months of openstatus, in one sentence: the work was always strategic, the bottleneck was always honesty, and the lever was always someone outside our own heads. Emily made us name the product. Alex made us redesign it. Shane made us go out and tell people about it. Colin made us a team of three. Moulik made us realize the community is here to ship. And the people in our Slack and Discord (the ones who file the GitHub issues, suggest the integrations, and tell us when we got something right) made the whole thing feel worth doing.
One nice thing to end on. A year ago, all our work with Emily was async, over a screen (that's even how the Reality Check described it). In May 2026 we finally met her in person, in Paris, at the Open Source Founders Summit she co-organizes: two days with other people building open-source companies, on the same community-vs-customers questions she first asked us. A year after the Reality Check, that felt like the circle closing.


PS: the best week of work is still the one where we ship a fix the same day a user asks for it. That hasn't changed. We hope it doesn't.
PPS: a small admission about why we can even draw this Mar 2025 → May 2026 comparison. When we went through the acquisition conversation last year, every number got bookmarked. Stars, followers, traffic, ARR, churn, retention, all frozen at that moment. That snapshot is what made this whole retrospective possible. So we're doing it again: bookmarking today's numbers (the ones in the tables above, plus the private ones in the appendix) as the next anchor. Whenever the next comparison happens, that's where we'll start from.
So: what are you avoiding?