Self-host the AI assistant with your own model
Jul 03, 2026 | by Moulik Aggarwal | [integrations]
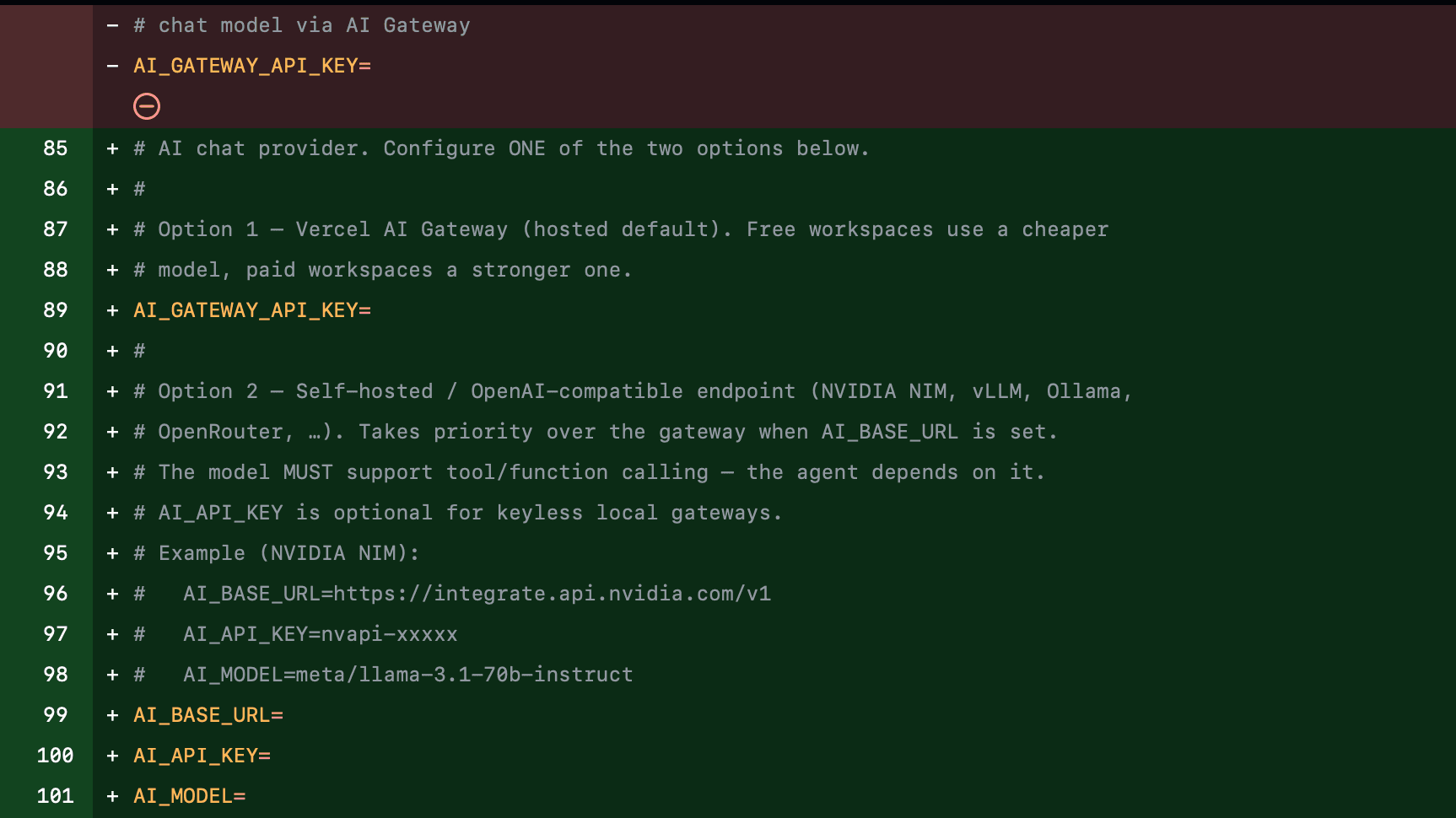
Running openstatus on your own infrastructure? The in-dashboard AI assistant no longer depends on a hosted gateway — you can now power it with your own model provider.
Point it at any OpenAI-compatible endpoint (NVIDIA NIM, vLLM, Ollama, OpenRouter, or a private gateway) by setting three environment variables in your .env.docker:
AI_BASE_URL=https://integrate.api.nvidia.com/v1
AI_API_KEY=nvapi-xxxxx
AI_MODEL=meta/llama-3.1-70b-instruct
The model and API key stay entirely on your own infrastructure, and AI_API_KEY is optional for keyless local gateways like Ollama. The only requirement is that the model supports tool calling, which the assistant uses to manage your monitors and status pages.
See the self-hosting guide for the full configuration.